2021-12-14
Lessons learnt forcing data science measures upon my colleagues
Keywords: communication, explanation, classification measuresWhile working at bol.com as a data analyst it fell upon me to revamp the KPIs of our team. There was a set of metrics in place from before I started working there, but they didn’t quite cut it anymore. While they provided basic and sometimes useful insights, they didn’t really allow the team to take meaningful action. Tasked with improving upon the existing KPIs, my thoughts landed upon a few classic data science measures. While implementing them was relatively straightforward, getting my colleagues onboard proved more challenging.
One of the most important things we did as a team was make sure fraudulent orders were never shipped out. Sending items to fraudsters resulted in write-offs (i.e. lost money), which was of course something we desperately tried to avoid. Initially we used those write-offs as an indicator of our performance. The problem with this approach was twofold. Firstly, the write-offs could fluctuate due to circumstances outside of our control: one week you simply have more active fraudsters than the next. Secondly, optimising for this metric came — at least in theory — at the cost of preventing orders from legitimate customers. If we set out to eliminate write-offs completely, our easiest course of action would have been to not allow a single order. Needless to say this makes for a poor business model.
So we needed a more sophisticated approach, and ideally a more sophisticated way of measuring our success. The attentive reader will have noticed that the process I described above is a textbook example of a classification problem. Orders are either legitimate or fraudulent, and we can either accept or reject them.
In data science there are four to ten main ways to measure the quality of your classifications, depending on whom you ask. Here I will stick to the four I tend to use most often: accuracy, precision, recall, and F1. In the existing situation where we measured write-offs we had for all intents and purposes settled upon a recall score. When you compare the write-offs with the total sum of cancelled orders you can calculate your recall. On the other hand we were not paying too close attention to the precision of our classification (i.e. the rate of false positives; legitimate customers whose orders were cancelled). That left our quality assessment rather lopsided.
I therefore wanted to use a measure that combines both sides of the coin. While accuracy is an intuitive measure that in essence does so, it only really holds up when you have an even distribution. Fraud detection, however, is a classic example of a classification where you have an uneven distribution. Only a slim minority of your orders is actually placed by fraudsters, while the vast majority is placed by honest customers. You could accept each and every order, including those from fraudsters, and still end up with an accuracy of 0.999.
Given this it made sense to me to implement an F1 score as our KPI, which combines both precision and recall into one score. This allowed us to take the effects of both types of classification errors into consideration. A false negative resulted in a write-off and lower recall, while a false positive resulted in an angry customer and lower precision. Both lower precision and lower recall resulted in a lower F1 score.
I would love to end this post here by stating that this new KPI solved all of our problems and we lived happily ever after. Truth be told, though, its implementation resulted in a few new challenges. While people with a background in data analysis/science/engineering are used to dealing with the measures I listed above, this is hardly the case for everyone else. As I mentioned accuracy is an intuitive measure; F1 is decidedly not that. While I stand by using an F1 score as our KPI, I cannot deny that this came at an initial cost to the interpretability of that KPI.
And that realisation led me to learn a lot about communicating data. Getting everyone on board with the new KPI pushed me to explain data in a few ways that were new to me. There are three takeaways I would like to share from that learning process:
1. Use analogies
When throwing around terms such as recall, type 1 error, and F1 people tend to get lost in the jargon. Using a simple but consistent analogy allowed me to reduce those terms to concrete concepts. In this case I used the analogy of a pond full of fish and junk throughout my entire explanation.
We wanted to keep the fish (= legitimate customers) swimming in the pond, while cleaning up the pieces of junk (= fraudsters). This translated, for example, false positives to dead fish, false negatives to junk left in the pond, and recall to the ratio of junk we managed to remove from the pond. I think analogies provide a mental anchor to go back to later, thus improving the memorability of your explanation. Later on, when discussing our KPIs, my colleagues would often refer back to the pond full of fish and junk.
 A pond full of fish and shoes as
an analogy for customers.
A pond full of fish and shoes as
an analogy for customers.
2. Use illustrations
As a data analyst/scientist/engineer you probably know that the people around you prefer to look at data visualisations rather than the raw data. Visualisations are, after all, a great way to convey information. I have found that this not only holds true for visualisations of numbers and metrics, but also for concepts themselves.
For concepts we should probably use the term “illustration” rather than “visualisation”, but the idea behind it is the same. Showing your audience something that supports your explanation adds an extra dimension, thus improving learning effectiveness. When combined with the use of analogies, you can use illustrations to really stand out and ingrain your explanation. To misappropriate the classic film-making adagium: “show, don’t tell”.
In this case I decided to draw the illustrations by hand. I got inspired to do so after following a workshop where some of the slides were hand-drawn. I’m not entirely sure why, but those really stood out to me and made the presentation more engaging. I will concede that this greatly increases the amount of work required, though. Especially when — like me — you’re not a great artist per se and keep redoing drawings.
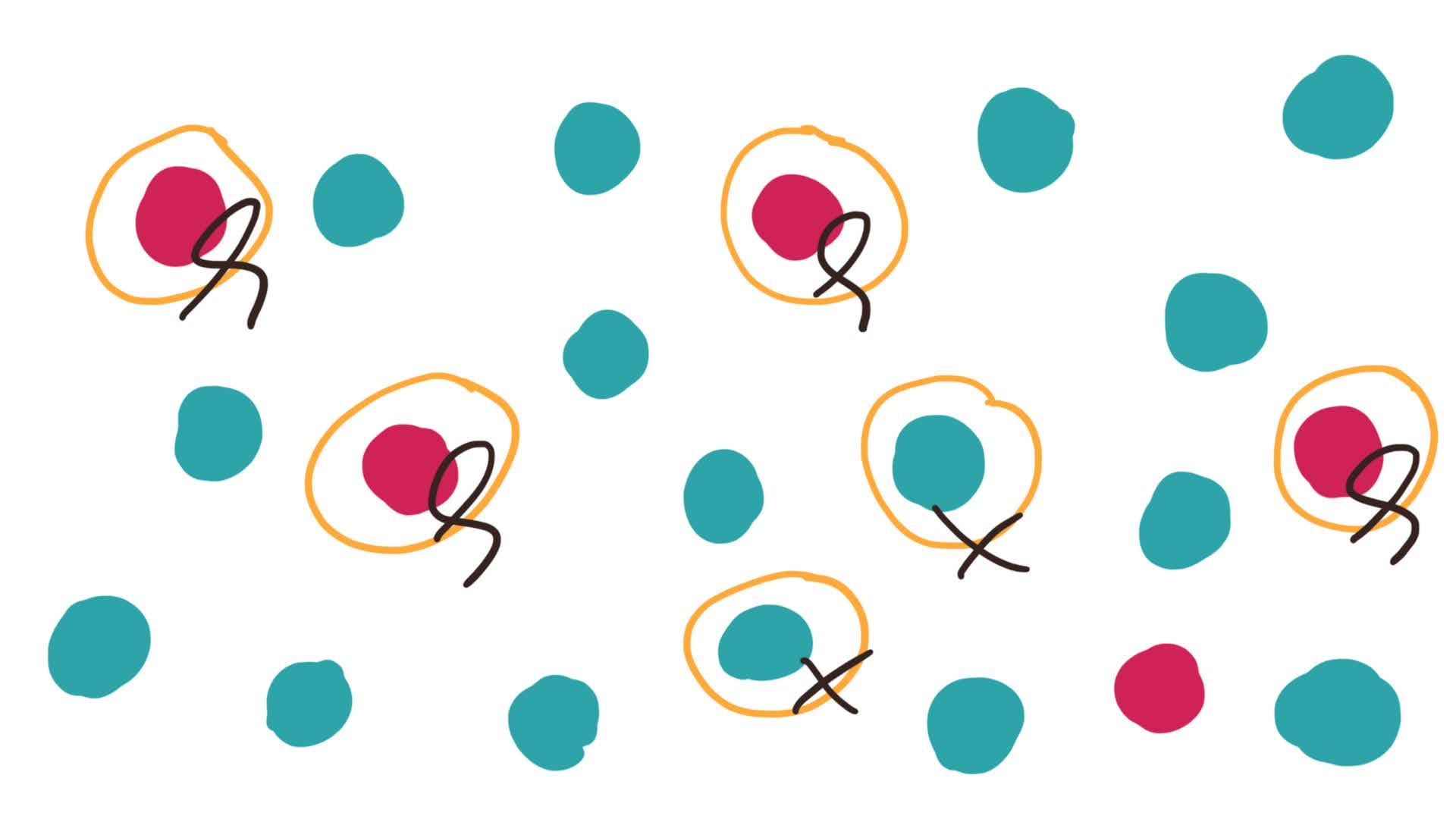 Illustration of the correctness of
selected items in classification.
Illustration of the correctness of
selected items in classification.
3. Use questions or exercises
In my elementary school it was a staple of student presentations: the quiz at the end. I won’t advocate for confronting your audience with trivia questions that are meant to check whether they paid attention. Good questions or exercises can, however, be used effectively to let your audience reason through the materials you explained earlier. Moreover, they point out which concepts you didn’t explain well enough yet. This allows you to revisit those concepts and elaborate further upon them. Take the following question for example:
“What happens to the junk in the pond when you improve your recall?”A question like this pushes your audience to reason through the relations between false negatives, true classifications, and the recall score. And if they go sideways in their reasoning, you know you should dive deeper into the topic.
 Quiz questions at the end of a
presentation to engage with the audience.
Quiz questions at the end of a
presentation to engage with the audience.
Conclusion
Applying a bunch of data science measures to an entire business process led me to learn a lot about communicating data effectively. With a few years of education and/or experience in this field it can become easy to take a certain level of data literacy for granted. As practitioners we should not forget about that gap in expertise and assume that the data speaks for itself. I have fallen in this trap many times, and have seen others in our field do so as well.
The ability to bridge that knowledge gap through solid communication might just be on of the core differences between a good data analyst/scientist/engineer and a great one. Although I am not even sure if the KPI I implemented is still in use, the experience provided me with a few extra tools in my communication arsenal. Even though that might not make me a great analyst/scientist/engineer yet, at least I am a better one for it.

Rob de Wit-Liezenga
I like working with data and tech to help people solve problems. Although I am comfortable with the "harder" aspects of data engineering and data science, I firmly believe that tech shouldn't be self-serving. What I like doing best is connecting with people, sharing knowledge, and discovering how data can help improve life and work.
linkedin.com/in/rcdewit